TL;DR
- LLM에 프롬프트 엔지니어링으로 추천 엔진(ranker)을 얻을 수 있다.
- sequential prompting에 비해 recency-focused나 in-context learning 을 사용해 프롬프트를 구성하면, NDCG를 높일 수 있었다.
- candidate generations에 bootstrapping 기법을 사용해, candidate의 위치 편향성을 완화할 수 있었다.
- 사용자 행동 내역의 개수를 적게 넣으면, top-1 상품의 인기도가 줄어드는 것을 확인할 수 있었다.
- instruction 튜닝 모델의 NDCG가 더 높았다.
- 모델 파라미터 개수가 큰 모델의 NDCG가 더 높았다.
제목: Large Language Models are Zero-Shot Rankers for Recommender Systems
초록(Abstract)
최근 대규모 언어 모델(LLM)(예: GPT-4)은 추천 작업에 접근할 수 있는 잠재력을 포함하여 인상적인 범용 작업 해결 능력을 보여주었습니다. 이러한 연구의 연장선상에서 본 연구는 추천 시스템의 랭킹 모델 역할을 하는 LLM의 역량을 조사하는 것을 목표로 합니다. 실증 연구를 수행하기 위해 먼저 순차적 상호작용 이력을 조건으로, 후보 생성 모델에 의해 검색된 상품을 후보로 간주하여 추천 문제를 조건부 랭킹 작업으로 공식화합니다. 그리고 순차적 상호작용 이력, 후보 상품, 랭킹 명령어를 포함하여 프롬프트 템플릿을 신중하게 설계하여 LLM으로 랭킹 과제를 해결하는 특정 프롬프트 접근 방식을 채택합니다. 추천 시스템에 널리 사용되는 두 가지 데이터 세트에 대한 광범위한 실험을 수행하여 추천 시스템에서 LLM을 사용하기 위한 몇 가지 주요 결과를 도출했습니다. LLM이 여러 후보 생성기가 검색한 후보에 대해 기존 추천 모델과 동등하거나 더 나은 제로샷 랭킹 능력을 가지고 있음을 보여줍니다. 또한 LLM이 과거 상호작용의 순서를 인식하는 데 어려움을 겪고 위치 편향과 같은 편향의 영향을 받을 수 있지만, 특별히 설계된 프롬프트 및 부트스트랩 전략을 통해 이러한 문제를 완화할 수 있음을 입증했습니다. 이 연구를 재현하는 코드는 https://github.com/RUCAIBox/LLMRank 에서 확인할 수 있습니다.
1 .개요(Introduction)
추천 시스템 관련 문헌에 따르면, 대부분의 기존 모델은 특정 도메인 또는 작업 시나리오의 사용자 행동 데이터로 학습되며[25, 13, 14], 두 가지 주요 문제를 가지고 있습니다. 첫째, 기존 모델은 주로 클릭한 상품 시퀀스와 같은 과거 상호작용 행동에서 사용자 선호도를 포착하기 때문에[14, 19, 39, 17] 실제 사용자 선호도를 명시적으로 이해하기 어렵고, 복잡한 사용자 관심사(예: 자연어로 표현된 사용자 의도)를 모델링하는 데 표현력이 제한적입니다. 둘째, 이러한 모델은 본질적으로 "좁은 전문가"로서 배경 지식이나 상식적인 지식에 의존하는 복잡한 추천 작업을 해결하는 데 있어 보다 포괄적인 지식이 부족합니다[11].
추천 성능과 상호작용을 개선하기 위해 추천 시스템에서 사전 학습된 언어 모델(PLM)을 사용하려는 노력이 증가하고 있습니다[10, 18, 31]. 이러한 모델은 자연어로 사용자 선호도를 명시적으로 포착하거나[10] 텍스트 코퍼스로부터 풍부한 세계 지식을 전송하는 것을 목표로 합니다[18, 16]. 이러한 효과에도 불구하고 작업별 데이터에 대한 추천 모델을 철저하게 미세 조정해야 하므로 다양한 추천 작업을 해결하기에는 역량이 떨어집니다[18]. 최근에는 대규모 언어 모델(LLM)이 상식적 추론, 지식 활용, 작업 일반화에서 우수한 역량을 보여줌으로써[37] 제로샷 작업 해결사 역할을 할 수 있는 큰 잠재력을 보여주었습니다[32, 27]. 실제로 추천 과제를 해결하기 위해 LLM을 사용하는 몇 가지 예비적 시도가 있습니다[9, 29, 30, 5, 21, 34]. 이러한 연구들은 주로 LLM으로 유능한 추천자를 구축할 수 있는 가능성을 논의하는 데 초점을 맞추고 있으며, 예비 실험을 바탕으로 유망한 결과를 보고하고 있습니다. 반면, 본 논문에서는 이러한 능력을 보다 상세하고 심층적으로 분석하고, LLM이 과거 상호작용 데이터를 통해 학습하는 방법과 같은 능력 보유 요인을 이해하는 데 초점을 맞추고자 합니다.
본 논문에서는 보다 상세한 실증 연구를 통해 추천 모델 역할을 하는 LLM의 역량을 살펴보고자 합니다. 일반적으로 추천 시스템은 다단계 후보 생성(연관성이 높은 상품 검색)과 랭킹(연관성이 높은 상품에 높은 순위 부여) 절차로 구성된 파이프라인 아키텍처[4]로 개발됩니다. 논문에서 다룰 작업은 주로 추천 시스템의 랭킹 단계에 초점을 맞추고 있는데, 이는 대규모 후보 세트에서 LLM을 실행하는 데 비용이 더 많이 들기 때문입니다. 또한, 랭킹 성능은 검색된 상위 순위 후보 상품에 민감하게 반응하기 때문에 LLM의 추천 능력의 미묘한 차이를 조사하는 데 더 적합합니다.
이 연구를 수행하기 위해 먼저 LLM의 추천 프로세스를 조건부 랭킹 작업으로 공식화합니다. 순차적인 과거 상호작용을 '조건'으로 포함하는 프롬프트가 주어지면, LLM은 후보 상품과 과거 상호작용한 상품 간의 관계에 대한 LLM의 내재적 지식에 따라 일련의 '후보'(예: 후보 생성 모델에 의해 검색된 상품)의 순위를 매기도록 지시받습니다. 그런 다음, 각각 '조건'과 '후보'에 대한 특정 구성을 설계하여 랭커로서 LLM의 경험적 성능을 체계적으로 연구하기 위해 통제된 실험을 수행합니다. 전반적으로 다음과 같은 주요 질문에 답하고자 합니다:
- LLM이 순차적인 상호작용이 있는 프롬프트에서 기본 사용자 선호도를 포착할 수 있는가?
- LLM이 내재적 지식을 활용하여 다양한 실제 전략으로 검색된 후보의 순위를 매길 수 있는가?
저희는 추천 시스템에 널리 사용되는 두 가지 공개 데이터 세트를 대상으로 실증 실험을 진행했습니다. 실험을 통해 추천 시스템을 위한 강력한 랭킹 모델로 LLM을 개발하는 방법에 대한 몇 가지 주요 결과를 도출했습니다. 이 실증 연구의 주요 결과를 요약하면 다음과 같습니다:
- LLM은 개인화된 랭킹을 위해 과거 행동을 활용할 수 있지만, 주어진 순차적 상호작용 이력의 순서를 인식하는 데는 어려움을 겪습니다.
- 최근 중심 프롬프트(recency-focused prompting) 및 문맥 학습(in-context learning)과 같이 특별히 설계된 프롬프트를 사용하면 LLM이 순차적인 과거 상호 작용의 순서를 인식하도록 트리거하여 랭킹 성능을 개선할 수 있습니다.
- LLM은 기존의 제로 샷 추천 방법보다 성능이 뛰어나며, 특히 서로 다른 실제 전략을 사용하는 여러 후보 생성 모델에서 검색된 후보에 대해 유망한 제로 샷 순위 지정 능력을 보여줍니다.
- LLM은 순위를 매기는 동안 포지션 편향과 인기 편향이 발생하는데, 이는 프롬프트 또는 부트스트랩 전략을 통해 완화될 수 있습니다.
2. 랭커로서 LLM을 고려한 일반 프레임워크(General Framework for LLMs as Rankers)
LLM의 추천 능력을 조사하기 위해 먼저 추천 프로세스를 조건부 랭킹 작업으로 공식화합니다. 그런 다음 추천 작업을 해결하기 위해 LLM을 적용하는 일반적인 프레임워크를 설명합니다.
2.1 문제 공식화(Problem Formulation)
한 사용자의 과거 상호작용 H = {i_1, i_2, . . . , i_n}(상호작용 시간 순서대로)를 조건으로 주어졌을 때, 관심 있는 상품이 더 높은 순위에 오를 수 있도록 후보 상품 C = {i_j}, j=1, 2, …, m의 순위를 매기는 것이 과제입니다. 실제로 후보 상품은 일반적으로 전체 상품 집합 I(m << |I|)에서 후보 생성 모델에 의해 검색됩니다[4]. 또한, 각 상품 i는 [18]에 따라 설명 텍스트 t_i와 연관되어 있다고 가정합니다.
2.2 자연어 명령을 사용해 LLM으로 순위 매기기(Ranking with LLMs Using Natural Language Instructions)
우리는 명령 추종 패러다임(instruction-following paradigm)에서 위에서 언급한 과제를 해결하기 위해 LLM을 랭킹 모델로 사용합니다[32]. 구체적으로, 먼저 각 사용자에 대해 순차적인 상호작용 이력 H(조건)와 검색된 후보 상품 C(후보)를 각각 포함하는 두 개의 자연어 패턴을 구성합니다. 그런 다음 이러한 패턴을 최종 명령어로 자연어 템플릿 T에 채웁니다. 이러한 방식으로 LLM은 명령어를 이해하고 명령어가 제시하는 대로 순위 결과를 출력합니다. LLM에 의한 랭킹 접근 방식의 전체 프레임워크는 그림 1에 나와 있습니다. 다음은 접근 방식의 세부적인 명령어 설계에 대해 설명합니다.

그림 1: 제안된 LLM 기반 제로샷 개인화 랭킹 방법 개요
순차적 과거 상호작용. LLM이 과거 사용자 행동에서 사용자 선호도를 파악할 수 있는지 알아보기 위해, 순차적 과거 상호작용 H를 LLM의 입력으로 명령에 포함시킵니다. LLM이 과거 상호작용의 순차적 특성을 인식할 수 있도록 하기 위해 세 가지 방법으로 명령을 구성할 것을 제안합니다:
- 순차적 프롬프트: 과거 상호작용을 시간 순서대로 정렬합니다. 이 방법은 이전 연구에서도 사용되었습니다[5]. 예를 들어, "나는 과거에 다음과 같은 영화를 순서대로 시청했습니다: '0. 멀티플리시티', '1. 쥬라기 공원', . . .".
- 최근 중심 프롬프트: 순차적인 상호작용 기록에 더해 가장 최근의 상호작용을 강조하는 문장을 추가할 수 있습니다. 예를 들어, '나는 과거에 다음과 같은 영화를 순서대로 시청했습니다: '0. 멀티플리시티', '1. 쥬라기 공원', .... 가장 최근에 본 영화는 죽은 대통령입니다. . . .".
- 상황 내 학습(In-Context Learning): ICL은 LLM이 다양한 작업을 풀기 위한 대표적인 프롬프트 방식[37]으로, 프롬프트에 데모 예시(작업 설명과 함께 제공 가능)를 포함하고 LLM이 특정 작업을 풀도록 지시합니다. 개인화된 추천 작업의 경우, 사용자마다 선호도가 다르기 때문에 단순히 다른 사용자의 예시를 소개하는 것은 노이즈가 발생할 수 있습니다. 저희 설정에 ICL을 적용하여 입력 상호작용 시퀀스 자체를 보강하여 데모 예시를 소개합니다. 세부적으로는 입력 인터랙션 시퀀스의 접두사와 그에 해당하는 후속 시퀀스를 예로 들어 설명합니다. 예를 들어, '내가 과거에 다음 영화를 순서대로 본 적이 있다면: '0. 멀티플리시티', '1. 쥬라기 공원', ... 순으로 본 적이 있다면, 죽은 대통령을 추천해야 하고, 이제 내가 죽은 대통령을 봤으니 ..."와 같은 식입니다.
검색된 후보 상품. 일반적으로 순위를 매길 후보 상품은 여러 후보 생성 모델에 의해 먼저 검색됩니다[4]. LLM으로 이러한 후보 상품의 순위를 매기기 위해 후보 상품 |C|를 순차적으로 정렬하기도 합니다. 예를 들어, "이제 다음에 볼 수 있는 후보 영화는 20개입니다: '0. 시스터 액트', '1. 선셋 블러바드', . . .". 전통적인 후보 생성 방식[4]에 따라 후보 상품에 대한 특정 순서가 정해져 있지 않다는 점에 유의하세요. 서로 다른 후보 생성 모델에서 검색된 결과에 대해 합집합을 얻고 후보 상품에 무작위로 위치를 할당합니다. 논문에서 다룰 작업에서는 상대적으로 작은 후보 풀을 고려하고 순위를 매기기 위해 20개의 후보 상품(즉, m = 20)을 유지합니다.
표 1: 전처리 후 데이터 집합의 통계입니다. "Avg. |H|"는 과거 사용자 행동의 평균 길이를 나타냅니다. "Avg. |t_i|"는 상품의 설명 텍스트에 포함된 토큰의 평균 개수를 나타냅니다.
LLM은 프롬프트의 예시 순서에 민감하다는 것이 밝혀졌습니다 [38, 22]. 이에 따라 프롬프트에서 후보 상품의 순서를 다르게 생성하여 LLM의 순위 결과가 후보의 배열 순서, 즉 위치 편향에 영향을 받는지 여부와 부트스트래핑을 통해 위치 편향을 완화하는 방법을 추가로 검토할 수 있습니다.
대규모 언어 모델로 순위 매기기. 기존 연구에 따르면 LLM은 자연어 명령어를 따라 제로 샷 또는 소수 샷 환경에서 다양한 작업을 해결할 수 있습니다 [32, 37]. LLM을 랭킹 모델로 사용하기 위해 최종적으로 위에서 언급한 패턴을 명령 템플릿 T에 통합합니다. 명령 템플릿의 예는 다음과 같이 주어질 수 있습니다: "[순차적인 과거 상호작용을 포함하는 패턴 H] [검색된 후보 상품을 포함하는 패턴 C] 나의 시청 이력에 따라 다음에 가장 보고 싶은 가능성을 측정하여 이 영화들의 순위를 매겨주세요. 주어진 후보 영화에 반드시 순위를 매겨야 합니다. 주어진 후보 목록에 없는 영화는 생성할 수 없습니다.".
LLM의 출력 파싱하기. 명령어를 LLM에 입력하면 추천을 위한 LLM의 순위 결과를 얻을 수 있습니다. LLM의 출력은 여전히 자연어 텍스트로 되어 있으며, 휴리스틱 텍스트 매칭 방법으로 출력을 파싱하고 지정된 상품 세트에 대한 추천 결과를 기반으로 합니다. 구체적으로, 영화 제목과 같이 상품의 텍스트가 짧고 변별력이 있는 경우에는 LLM 출력과 후보 상품의 텍스트 간에 KMP[20]와 같은 효율적인 하위 문자열 매칭 알고리즘을 직접 수행할 수 있습니다. 또는 각 후보 상품에 인덱스를 할당하고 LLM에 직접 순위가 매겨진 인덱스를 출력하도록 지시할 수 있습니다. 프롬프트에 후보 상품이 포함되어 있음에도 불구하고 LLM이 후보 세트에서 벗어난 상품을 생성하는 경향이 있다는 사실을 발견했습니다. 반면, 이 오류의 비율은 GPT-3.5의 경우 약 3%로 매우 적습니다. 이 경우 LLM에 이 오류를 상기시키거나 단순히 잘못된 추천으로 처리할 수 있습니다.
3. 실증 연구(Empirical Studies)
우리는 순차적 기록 상호작용 H, 후보 C, 템플릿 T를 포함한 다양한 구성의 효과를 조사하고, 두 가지 연구 질문에 답하는 데 초점을 맞추고자 한다: (a) LLM이 사용자 순차적 기록 상호작용 H가 있는 프롬프트에서 사용자 선호도를 포착할 수 있는가? (b) LLM이 내재적 지식을 활용하여 다양한 실제 전략으로 검색된 후보 C의 순위를 매길 수 있는가?
데이터 세트. 실험은 추천 시스템에 널리 사용되는 두 가지 공개 데이터 세트, 즉 (1) 사용자 평점이 상호작용으로 간주되는 영화 평점 데이터 세트 MovieLens-1M [12](줄여서 ML-1M)과 (2) 리뷰가 상호작용으로 간주되는 Amazon 리뷰 데이터 세트 [23]의 게임 카테고리 1개에 대해 수행됩니다. 상호작용이 5개 미만인 사용자와 상품을 필터링합니다. 그런 다음 각 사용자의 상호작용을 타임스탬프별로 정렬하고 가장 오래된 상호작용부터 정렬하여 해당 과거 상호작용 시퀀스를 구성합니다. 영화/제품 제목은 상품의 설명 텍스트로 사용됩니다.
평가 구성. 기존 연구[19, 18, 17]에 따라 평가 시에는 리브 원 아웃(leave-one-out) 전략을 적용합니다. 각 과거 상호작용 시퀀스에 대해 마지막 상품이 기준값 상품으로 사용됩니다. 주어진 m개의 후보에 대한 순위 결과를 평가하기 위해 널리 사용되는 메트릭인 NDCG@N을 채택합니다(여기서 N ≤ m).
구현 세부 사항. 이 작업의 재현을 용이하게 하기 위해 널리 사용되는 오픈 소스 추천 라이브러리 RECBOLE [36, 35, 33]을 사용하여 실험을 수행합니다. 순차적인 과거 사용자 행동의 경우, 기본적으로 가장 최근 50개의 상호작용을 사용합니다. LLM 기반 방법의 경우, 각 데이터 세트에 대한 과거 행동과 함께 200명의 사용자를 무작위로 샘플링합니다. SASRec[19]과 같은 기존 기준 방법(baseline)의 경우, 지정되지 않는 한 훈련 데이터 세트의 모든 상호 작용에 대해 훈련되며, 평가된 LLM은 OpenAI의 API gpt-3.5-turbo1을 호출하여 액세스합니다. LLM 호출의 하이퍼파라미터 온도(temperature)는 0.2로 설정됩니다. 보고된 모든 결과는 무작위성의 영향을 줄이기 위해 최소 3회 반복 실행의 평균입니다.
그림 2: LLM이 과거 사용자 행동을 활용하는지 여부와 LLM이 상호작용 기록의 순서를 인지하는지 여부를 분석합니다.
3.1 LLM이 순차적인 과거 사용자 행동과 관련된 프롬프트를 이해할 수 있나요?(Can LLMs Understand Prompts that Involve equential Historical User Behaviors?)
기존 문헌에서 과거 사용자 행동은 주로 특수하게 설계된 추천 모델에 의해 그래프[13] 또는 시퀀스[14]로 모델링됩니다. 반면, 본 연구에서는 과거 사용자 행동을 프롬프트로 인코딩하여 추천을 위해 특별히 훈련되지 않은 대규모 언어 모델에 입력합니다. 이 부분에서는 먼저 LLM이 이러한 과거 사용자 행동을 활용하여 정확한 추천을 할 수 있는지 여부를 조사합니다. 다양한 H 구성을 설계하여 (1) LLM이 과거 행동이 있는 프롬프트를 이해하고 그에 따라 순위를 매길 수 있는지, (2) 순차적 특성이 사용자 선호도를 이해하는 데 인식되고 활용되는지, (3) LLM이 장기적인 사용자 이력을 더 잘 활용할 수 있는지 등을 살펴보고자 합니다.
이 섹션의 실험은 주로 과거 사용자 행동의 효과에 초점을 맞추기 때문에, LLM의 랭킹 성능을 평가하기 위해 후보 집합을 구성하는 데 간단한 전략을 사용합니다. 구체적으로, 각 실측 데이터 상품에 대해 전체 상품 세트 I에서 m - 1 개의 상품을 네거티브 인스턴스로 무작위로 검색합니다(여기서 m = 20). 그런 다음 프롬프트를 구성하기 전에 이러한 후보 상품을 무작위로 섞습니다.
LLM은 과거 행동이 있는 프롬프트에 해당하는 개인화된 추천을 제공할 수 있습니다. 이 섹션에서는 LLM이 과거 사용자 행동이 있는 프롬프트를 이해하고 개인화된 추천을 제공할 수 있는지 여부를 살펴봅니다. 사용자의 과거 행동이 순차적으로 기록된 프롬프트가 주어지면, 하나의 실측 데이터 상품과 무작위로 샘플링된 부정 상품 19개를 포함하여 20개의 상품으로 구성된 후보 세트의 순위를 매기는 작업을 수행합니다. 과거 행동을 분석하여 관심 있는 상품에 더 높은 순위를 매겨야 합니다. 세 가지 LLM 기반 방법의 순위 결과를 비교합니다. (a) 2.2절에서 설명한 대로 LLM으로 순위를 매기는 방법. 과거 사용자 행동은 '순차적 프롬프트' 전략을 사용하여 프롬프트에 인코딩됩니다. (b) 기록 없음: 과거 사용자 행동이 지침에서 제거되고, (c) 가짜 기록: 원래 과거 행동의 모든 상품을 무작위로 샘플링된 가짜 과거 행동으로 대체합니다.
그림 2(a)를 보면, 과거 행동이 없거나 가짜 과거 행동이 있는 변종보다 우리의 변종이 더 나은 성능을 보이는 것을 알 수 있습니다. 이 결과는 LLM이 과거 사용자 행동이 포함된 프롬프트를 효과적으로 활용하여 개인화된 추천을 제공할 수 있는 반면, 관련 없는 과거 행동은 LLM의 순위 성능을 저해할 수 있음을 시사합니다.
LLM은 주어진 과거 사용자 행동의 순서를 인식하는 데 어려움을 겪습니다. 그림 2(b)에서는 사용자 과거 행동의 순차적 특성을 인식하는 LLM의 능력을 자세히 살펴봅니다. 접미사(랜덤 순서)가 붙은 변형은 과거 사용자 행동을 무작위로 섞어 모델에 입력하는 것을 의미합니다(당사 또는 SASRec). SASRec과 SASRec(무작위 순서)을 비교하면, 순차적인 과거 상호작용의 순서가 상품 순위에 매우 중요하다는 것을 알 수 있습니다. 그러나 우리와 우리의 (무작위 순서)의 성능은 매우 유사하며, 이는 LLM이 주어진 과거 사용자 행동의 순서에 민감하지 않다는 것을 나타냅니다.

표 2: 무작위로 검색된 후보에 대한 다양한 제로 샷 추천 모델의 성능 비교. 실측 데이터 상품은 후보 세트에 포함되도록 보장됩니다. 'full'는 대상 데이터 세트에 대해 학습된 추천 모델을 나타내고, 'zero-shot'은 대상 데이터 세트에 대해 학습되지는 않았지만 사전 학습될 수 있는 추천 모델을 나타냅니다. 세 가지 제로 샷 프롬프트 전략은 gpt-3.5-turbo를 기반으로 합니다. 제로샷 추천 방법 중 가장 우수한 성능을 굵은 글씨로 강조했습니다. N@K는 NDCG@K를 나타냅니다.
또한, 그림 2(c)에서는 프롬프트를 구성하는 데 사용되는 최신 사용자 행동 기록(|H|)의 수를 5개에서 50개까지 다양하게 설정했습니다. 그 결과, 과거 사용자 행동의 수를 늘린다고 해서 랭킹 성능이 향상되지 않으며, 심지어 랭킹 성능에 부정적인 영향을 미치는 것으로 나타났습니다. 이러한 현상은 LLM이 순서를 이해하기 어렵지만 모든 과거 행동을 동일하게 고려하기 때문에 발생하는 것으로 추측됩니다. 따라서 과거 사용자 행동이 너무 많으면(예: |H| = 50) LLM이 과부하가 걸려 성능이 저하될 수 있습니다. 반대로 상대적으로 작은 |H|를 사용하면 LLM이 가장 최근에 상호 작용한 상품에 집중할 수 있으므로 추천 성능이 향상됩니다. 위의 결과는 첫 번째 핵심 관찰로 요약할 수 있습니다:
관찰결과 1. LLM은 개인화된 순위를 위해 과거 행동을 활용할 수 있지만, 주어진 순차적 상호작용 기록의 순서를 인식하는 데 어려움을 겪습니다.
LLM이 상호작용 순서를 인식하도록 트리거하기. 위의 관찰 결과를 바탕으로 우리는 순차적 프롬프트 전략으로는 LLM이 상호작용 이력의 순서를 인식하기 어렵다는 것을 발견했습니다. 따라서 우리는 LLM의 순서 인식 능력을 이끌어내기 위한 두 가지 대안적인 프롬프트 전략을 제안합니다. 핵심 아이디어는 최근에 상호작용한 상품을 강조하는 것입니다. 제안된 최근성 중심 프롬프트와 문맥 내 학습 전략에 대한 자세한 설명은 섹션 2.2에 나와 있습니다.
표 2에서 최근 강제 프롬프트와 컨텍스트 내 학습 모두 LLM의 순위 지정 성능을 향상시킬 수 있음을 알 수 있습니다. 최신성 중심 프롬프트는 top-1 정확도를 더 잘 산출하는 반면, 인컨텍스트 학습은 과거 행동이 더 긴 데이터 세트에서 더 나은 성능을 발휘합니다. 위의 결과는 다음과 같은 주요 관찰 결과로 요약할 수 있습니다:
관찰결과 2. 최근성 중심 프롬프트 및 컨텍스트 내 학습과 같이 특별히 설계된 프롬프트를 사용하면 LLM이 과거 사용자 행동의 순서를 인식하도록 트리거하여 랭킹 성과를 개선할 수 있습니다.
3.2 제로 샷 설정에서 LLM이 후보 상품의 순위를 얼마나 잘 매길 수 있나요?(How Well Can LLMs Rank Candidate Items in a Zero-Shot Setting?)
이 섹션에서는 LLM이 후보의 순위를 얼마나 잘 매길 수 있는지 자세히 살펴봅니다. 먼저 벤치마킹 실험을 통해 기존 추천 모델, 기존 제로샷 추천 방법, 제안한 LLM 기반 방법 등 무작위 후보에 대한 다양한 방법 간의 순위 지정 성능을 비교합니다. 다음으로, 다양한 전략에 의해 검색된 하드 네거티브가 있는 후보에 대해 LLM 기반 방법을 평가하여 LLM의 순위가 무엇에 따라 달라지는지 자세히 살펴봅니다. 그런 다음, 보다 실용적이고 어려운 설정을 시뮬레이션하기 위해 여러 후보 생성 모델에 의해 검색된 후보에 대한 다양한 방법의 순위 성능을 비교하는 또 다른 벤치마크를 제시합니다.
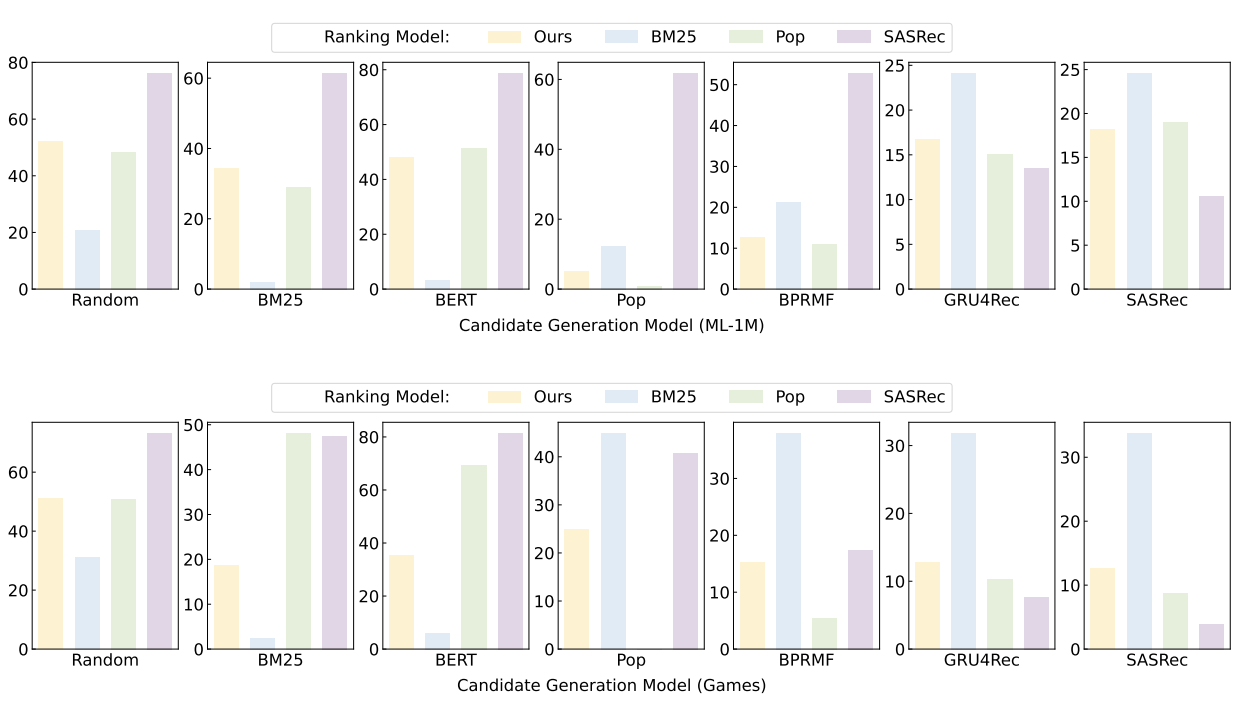
그림 3: 다양한 전략으로 검색된 하드 네거티브에 대해 NDCG@10(%)으로 측정한 순위 성과
LLM은 유망한 제로 샷 랭킹 능력을 가지고 있습니다. 표 2에서는 LLM 기반 방법과 기존 방법의 순위 결정 능력을 비교하기 위한 실험을 수행합니다. 섹션 3.1의 설정과 동일하게 |C| = 20으로 설정하고 후보 상품(지상 진실 상품 제외)을 무작위로 검색합니다. 훈련 세트에 대해 학습된 세 가지 기존 추천 모델, 즉 Pop(상품 인기도에 따른 추천), BPRMF [25], SASRec [19]을 포함합니다. 또한 BM25 [26](후보 간의 텍스트 유사성과 과거 상호작용에 따라 순위 지정), UniSRec [18], VQ-Rec [16] 등 대상 데이터 세트에서 학습되지 않은 세 가지 제로 샷 추천 방법도 평가합니다. UniSRec과 VQ-Rec의 경우, 공개적으로 사용 가능한 사전 학습된 모델을 사용합니다. ZESRec [7]은 사전 훈련된 모델이 공개되지 않았고, UniSRec은 이 모델의 개선된 버전으로 볼 수 있기 때문에 포함하지 않았습니다[18]. LLM 기반 방법의 경우, 섹션 2.2에 설명된 대로 서로 다른 프롬프트 전략을 사용하는 세 가지 변형을 시퀀셜이라는 이름으로 포함합니다.
표 2를 보면 LLM 기반 방식이 기존 제로샷 추천 방식보다 큰 폭으로 성능이 뛰어나며, 제로샷 랭킹에 대한 가능성을 보여주고 있음을 알 수 있습니다. ML-1M 데이터셋에서는 단순히 제목의 유사도만으로 영화 간의 유사도를 측정하기 어렵기 때문에 제로샷 추천을 수행하기 어렵다는 점을 강조하고 싶습니다. LLM 기반 모델은 내재적 세계 지식을 사용하여 영화 간의 유사성을 측정하고 추천할 수 있기 때문에 ML-1M에서 여전히 유망한 제로샷 랭킹 성능을 달성할 수 있음을 알 수 있습니다. 그러나 제로샷 추천 방법과 기존 방법 사이에는 여전히 격차가 존재하며, 이는 상호작용 데이터로부터 학습할 수 있는 LLM 기반 추천 방법을 개발하는 것이 중요하다는 것을 나타냅니다[34].
LLM은 상품 인기도, 텍스트 기능 및 사용자 행동에 따라 후보의 순위를 매깁니다. LLM이 주어진 후보의 순위를 매기는 방법을 더 자세히 조사하기 위해, 다양한 후보 생성 방법으로 검색된 후보에 대한 LLM의 순위 성능을 평가합니다. 이러한 후보들은 실사 상품에 대한 하드 네거티브로 볼 수 있으며, 특정 상품 범주에 대한 LLM의 순위 지정 능력을 측정하는 데 사용할 수 있습니다. (1) BM25 [26] 및 BERT [6]와 같은 콘텐츠 기반 방법은 과거에 상호 작용한 상품과 후보 간의 텍스트 특징 유사성을 기반으로 후보를 검색하고, (2) Pop(상품 인기도에 따라 추천), BPRMF [25], GRU4Rec [14], SASRec [19]를 포함한 상호작용 기반 방법은 사용자-상품 상호 작용에 대해 학습된 기존 추천 모델을 사용하여 상품을 검색합니다. 후보가 주어지면 LLM 기반 모델(Ours)과 대표적인 콘텐츠 기반(BM25) 및 상호 작용 기반(Pop 및 SASRec) 방법의 순위 성능을 비교합니다.
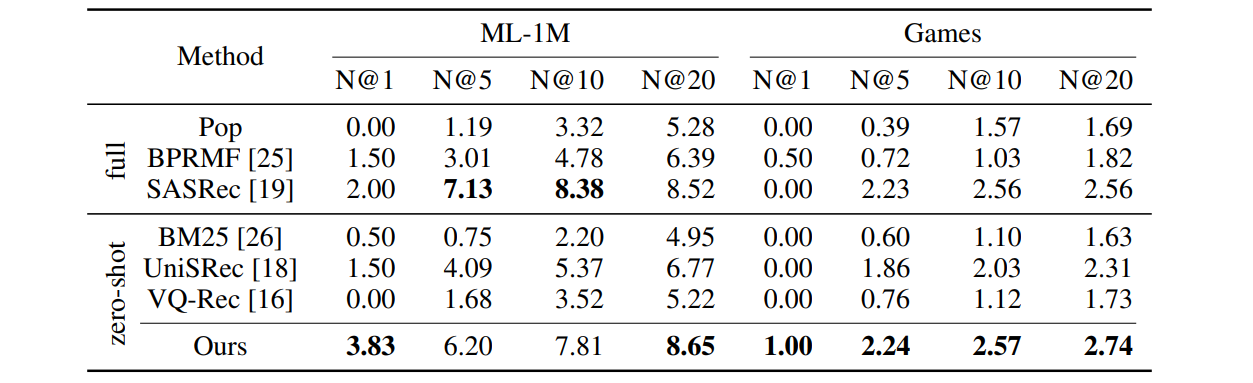
표 3: 여러 후보 생성 모델에 의해 검색된 후보에 대한 다양한 제로 샷 추천 모델의 성능 비교. 실측 데이터 상품이 후보 세트에 포함되는 것은 보장되지 않습니다. 'full'는 대상 데이터 세트에 대해 학습된 추천 모델을 의미하며, 'zero-shot'은 대상 데이터 세트에 대해 학습되지는 않았지만 사전 학습될 수 있는 추천 모델을 의미합니다. 모든 추천 방법 중 가장 우수한 성능을 굵은 글씨로 강조했습니다. N@K는 NDCG@K를 나타냅니다.
그림 3에서 LLM 기반 방법의 순위 성능은 후보 세트와 데이터 세트에 따라 달라지는 것을 볼 수 있습니다. (1) ML-1M의 경우, 인기 상품(예: Pop 및 BPRMF)이 포함된 후보 세트에서는 LLM 기반 방식이 높은 순위를 차지하지 못하며, 이는 LLM 기반 방식이 ML-1M 데이터 세트에서 상품의 인기도에 따라 추천 상품이 크게 좌우된다는 것을 나타냅니다. (2) 게임에서는 인기 후보와 텍스트 유사 후보 모두에서 비슷한 순위 성능을 보이는 것을 관찰할 수 있으며, 이는 상품 인기도와 텍스트 특징이 LLM의 순위에 유사하게 기여한다는 것을 보여줍니다. (3) 두 데이터 세트 모두에서, 상호작용 기반 후보 생성 방법에 의해 검색된 하드 네거티브의 영향을 받지만, SASRec과 같이 순전히 상호작용에 기반한 순위 모델만큼 심각하지는 않습니다. 위의 결과는 LLM 기반 방법이 순위를 매길 때 일부 단일 측면만 고려하는 것이 아니라 상품 인기도, 텍스트 기능, 심지어 사용자 행동까지 활용한다는 것을 보여줍니다. 데이터 세트에 따라 순위 성능에 영향을 미치는 이 세 가지 측면의 가중치도 달라질 수 있습니다.
LLM은 여러 후보 생성 모델에서 검색된 후보의 순위를 효과적으로 매길 수 있습니다. 실제 2단계(two-stage) 추천 시스템[4]의 경우, 순위를 매길 상품은 일반적으로 여러 후보 생성 모델에 의해 검색됩니다. 따라서 저희도 보다 실제적인 환경에서 벤치마킹 실험을 진행했습니다. 일반적인 콘텐츠 기반 및 인터랙션 기반 방법을 포괄하는 7가지 후보 생성 모델, 즉 Random, BM25, BERT, Pop, BPRMF, GRU4Rec, SASRec을 사용하여 상품을 검색합니다. 각 후보 생성 모델에서 검색된 상위 3개의 우수 상품은 총 21개의 상품이 포함된 후보 집합으로 병합됩니다. 보다 실용적인 설정으로, 3.1절에서 설명한 설정처럼 각 후보 세트에 실측 상품을 보완하지는 않습니다. 3.1절의 실험에서 영감을 얻은 저희의 경우, 최근성 중심의 프롬프트 전략을 사용하여 |H| = 5개의 순차적인 과거 상호작용을 프롬프트로 인코딩하여 적절한 랭킹 성능을 구현합니다.
표 3을 보면, LLM 기반 순위 모델(Ours)이 대부분의 지표(8개 중 6개)에서 비교 대상 추천 모델에 비해 가장 우수한 성능을 보이며, 심지어 대상 데이터세트에 대해 학습된 기존 추천 모델인 SASRec을 능가하는 것을 확인할 수 있습니다. 이 결과는 여러 후보 생성 모델에 의해 검색된 후보에 대한 LLM의 강력한 제로샷 랭킹 능력을 보여줍니다. 이러한 현상에 대해 우리는 LLM이 내재적 세계 지식을 활용하여 인기도, 텍스트 특징, 사용자 행동 등을 종합적으로 고려하여 후보의 순위를 매길 수 있다고 가정합니다. 이에 비해 기존 모델(좁은 의미의 전문가)은 복잡한 환경에서 상품의 순위를 매기는 능력이 부족할 수 있습니다. 위의 결과는 다음과 같이 요약할 수 있습니다:
관찰결과 3. LLM은 특히 다양한 실제 전략을 가진 여러 후보 생성 모델에 의해 검색된 후보에 대해 제로 샷 랭킹 능력을 가지고 있습니다.

그림 4: 다양한 크기의 후보 집합에 대한 LLM 기반 모델(Ours)과 기존 추천 모델(SASRec)의 순위 성능 비교.
LLM은 후보 집합이 클 경우 후보의 순위를 제대로 매길 수 없습니다. 언어 모델로 긴 시퀀스의 의미를 효과적으로 모델링하는 것은 기술적으로 어려운 과제였습니다[8]. 따라서 우리는 LLM이 순위를 매기기 위해 대규모 후보 집합을 처리할 수 있는지 조사하고자 합니다. 후보 |C|의 수를 5개에서 50개까지 다양하게 설정하고 그림 4에서 랭킹 성능을 보고합니다. LLM과 기존 추천 모델(예: SASRec) 간의 격차가 |C|가 증가할수록 커지는 것을 볼 수 있으며, 이는 많은 후보 상품 집합의 순위를 매길 때 LLM이 어려움에 직면할 수 있음을 나타냅니다.
3.3 LLM이 순위를 매길 때 편향성이 있나요?(Do LLMs suffer from biases while ranking?)
기존 추천 시스템의 편향과 디베이싱(debiasing) 방법은 널리 연구되어 왔습니다[2]. 제안된 LLM 기반 제로 샷 추천 모델의 경우에도 LLM의 순위에 영향을 미치는 특정 편향이 있을 수 있습니다. 이 섹션에서는 LLM 기반 추천 모델이 겪을 수 있는 두 가지 편향, 즉 위치 편향과 인기 편향에 대해 설명합니다. 또한 이러한 편향을 완화하는 방법에 대해서도 논의합니다.
후보 순서는 LLM의 순위 결과에 영향을 미칩니다. 기존의 랭킹 방식에서는 검색된 후보의 순서가 랭킹 결과에 영향을 미치지 않는 것이 일반적입니다. 그러나 2.2절에서 설명한 LLM 기반 접근 방식에서는 후보 상품이 순차적으로 배열되고 프롬프트에 LLM의 입력으로 인코딩됩니다. LLM은 일반적으로 자연어 처리 작업의 프롬프트에서 예제 순서에 민감하다는 것이 밝혀졌습니다 [38, 22]. 이에 따라 후보의 순서가 LLM의 랭킹 성능에 영향을 미치는지 실험을 진행했습니다. 3.1절에서 사용한 것과 동일한 후보 세트에 대해 LLM의 성능을 평가합니다. 유일한 차이점은 프롬프트에서 이러한 후보의 순서를 목적에 따라 제어한다는 것입니다. 즉, 프롬프트를 구성하는 동안 지상 진실 상품이 특정 위치에 나타나도록 합니다. 실측값 상품의 위치를 {0, 5, 10, 15, 19}로 변경하여 순위 결과를 그림 5(a)에 제시합니다. 실측값 상품이 다른 위치에 표시될 때 순위 성능이 달라지는 것을 볼 수 있습니다. 특히, 실측값 상품이 마지막 몇 개의 위치에 나타날 때 순위 성능이 크게 떨어집니다. 이 결과는 기존 추천 모델은 일반적으로 영향을 받지 않는 반면, LLM 기반 랭커의 경우 후보의 순서, 즉 위치 편향에 따라 LLM의 랭킹 성능이 영향을 받는다는 것을 나타냅니다.

그림 5: LLM 순위의 편향성 및 디베이싱 방법. (a) 프롬프트에서 후보자의 위치가 순위 결과에 영향을 미칩니다. (b) LLM은 인기 있는 아이템을 추천하는 경향이 있습니다. (c) 부트스트래핑은 위치 편향을 완화합니다. (d) 과거 상호작용에 초점을 맞추면 인기 편향이 줄어듭니다.
부트스트래핑을 통한 위치 편향성 완화. 그림 5(a)에서 볼 수 있듯이, LLM은 프롬프트의 뒷부분에 위치한 후보 상품의 순위를 낮게 매기는 경향이 있음을 알 수 있습니다. 후보 상품이 각 위치에 무작위로 할당되므로 위치 편향을 완화하기 위한 간단한 전략은 순위 프로세스를 부트스트랩하는 것입니다. 각 라운드마다 후보 상품을 무작위로 섞어 한 후보 상품이 다른 위치에 나타나 순위를 매길 수 있도록 후보 집합을 B회 반복하여 순위를 매길 수 있습니다.
순위를 매긴 후 더 높은 순위에 있는 상품에 더 높은 점수를 부여하고, 순위 점수를 합산하여 최종 순위를 도출합니다. 그림 5(c)에서 3.1절의 설정에 따라 부트스트랩 전략을 적용합니다. 각 후보 세트는 3번씩 순위를 매깁니다. 부트스트래핑이 두 데이터 세트 모두에서 랭킹 성능을 향상시킨다는 것을 알 수 있습니다.
후보의 인기도는 LLM의 순위 결과에 영향을 미칩니다. 인기 있는 상품의 경우 관련 텍스트가 LLM의 사전 학습 코퍼스에 자주 나타날 수도 있습니다. 예를 들어 베스트셀러 도서가 웹에서 널리 논의될 수 있습니다. 따라서 우리는 후보의 인기도에 따라 순위 결과가 영향을 받는지 살펴보고자 합니다. 하지만 사전 학습 코퍼스로는 상품 텍스트의 인기도를 직접 측정하기 어렵습니다. 따라서 하나의 추천 데이터셋에서 상품 빈도로 텍스트 인기도를 간접적으로 측정하여 반영할 수 있다는 가설을 세웠습니다. 그림 5(b)는 순위가 매겨진 상품 목록의 각 위치에 대한 상품 인기도 점수(훈련 세트에서 정규화된 상품의 출현 빈도로 측정)를 보여줍니다. 인기 있는 아이템이 더 높은 위치에 랭크되는 경향이 있음을 알 수 있습니다. 기존 추천 모델과 마찬가지로 LLM도 인기 편향이 발생하여 더 인기 있는 상품을 추천하는 것을 선호합니다.
LLM이 과거 상호작용에 초점을 맞추도록 하면 인기 편향을 줄이는 데 도움이 됩니다. 그림 5(b)를 보면 LLM이 인기 있는 상품의 순위를 더 높게 매기는 경향이 있음을 알 수 있습니다. 섹션 3.2의 관찰 결과에서 알 수 있듯이, 그 이유는 LLM이 과거 상호작용을 잘 활용하지 못하고 주로 상품 인기도에 따라 추천을 해야 하기 때문일 수 있습니다. 그림 2(c)의 실험을 통해, 사용된 과거 상호작용의 수가 적을 때 LLM이 과거 상호작용을 더 잘 활용할 수 있다는 것을 알 수 있습니다. 따라서, LLM이 사용자 이력에 더 집중할 때 인기도 편향이 줄어들 수 있는지 알아보기 위해 이력 상호작용의 수를 변화시켰습니다. 그림 5(d)에서 가장 높은 순위를 차지한 상품의 인기도 점수(정규화된 상품 빈도로 측정)를 비교해 보았습니다. 과거 상호작용 횟수가 감소함에 따라 인기도 점수도 감소하는 것을 확인할 수 있습니다. 이는 LLM이 과거 상호작용에 집중하도록 강제할 때 인기도 편향의 영향을 줄일 수 있음을 시사합니다. 위의 실험을 통해 다음과 같은 결론을 내릴 수 있습니다:
관찰결과 4. LLM은 순위를 매기는 동안 포지션 편향과 인기 편향을 겪게 되는데, 이는 특별히 고안된 프롬프트 또는 부트스트랩 전략을 통해 완화할 수 있습니다.
3.4 LLM은 어떻게 추천 능력을 얻나요?(How Do LLMs Gain Recommendation Abilities?)
이 섹션에서는 어떤 요인이나 기법이 LLM의 랭킹 능력에 기여하는지 살펴봅니다. 특히 명령 튜닝과 모델 스케일링이라는 두 가지 요인이 LLM의 랭킹 능력에 미치는 영향을 주로 살펴보는데, 이 두 가지 기법이 LLM의 능력에 핵심적인 역할을 하는 것으로 나타났기 때문입니다[37, 1, 32]. 앞으로는 이 두 가지 기법이 LLM의 추천 성능을 어떻게 향상시키는지에 대해 좀 더 집중적으로 연구하고자 합니다.
명령어 튜닝은 LLM의 순위 결정 능력을 향상시킵니다. 기존 연구에 따르면 명령어 튜닝은 보이지 않는 작업에 대한 LLM의 일반화 능력을 크게 향상시키는 것으로 나타났습니다 [27, 32]. 여기서는 LLM을 사용하여 과거 상호작용에 따라 상품의 순위를 매기는 능력이 명령어 튜닝을 통해 향상될 수 있는지 알아보고자 합니다. 3.1절의 실험 설정에 따라 제안한 LLM 기반 랭킹 방법의 기본 LLM을 gpt-3.5-turbo에서 (1) LLaMA [28]와 같이 명령어 튜닝을 하지 않은 LLM과 (2) Vicuna [3], text-davinci-0032와 같이 명령에 대한 미세 튜닝을 한 LLM으로 교체한 후 이들에 랭킹 작업을 수행하도록 인스트럭션을 내립니다. 그림 6에서 Vicuna-7/13B와 LLaMA-7/13B를 비교하면 명령어 튜닝을 거친 LLM이 명령어 튜닝을 거치지 않은 LLM보다 성능이 뛰어나다는 것을 알 수 있습니다. 이 결과는 명령어 튜닝이 추천 작업을 위해 특별히 설계된 명령어가 아니더라도 LLM의 순위 지정 능력을 향상시킨다는 것을 보여줍니다.
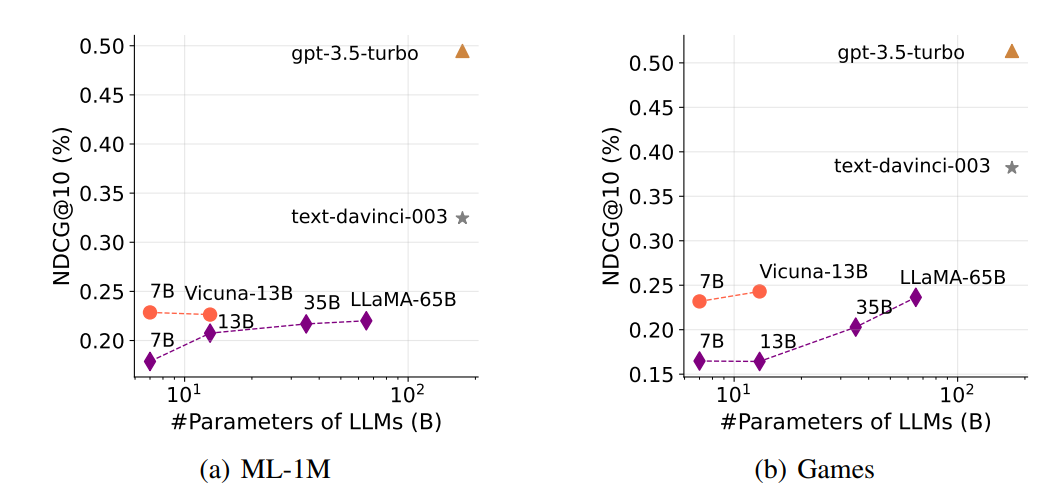
그림 6: 다양한 LLM을 사용한 랭킹 성능 비교
모델 스케일링은 LLM의 랭킹 성능을 향상시킵니다. 스케일링 법칙에서 알 수 있듯이, 모델 크기와 훈련 데이터의 양이 증가함에 따라 다양한 다운스트림 작업에서 LLM의 성능은 일반적으로 향상됩니다 [24, 15, 28]. 3.1절의 실험 설정에 따라 기본 LLM을 다양한 크기(7B, 13B, 35B, 65B)의 LLaMA로 대체하여 제로 샷 추천 작업에 대한 모델 스케일링의 효과를 조사합니다. 그림 6을 보면 모델 크기가 커질수록 LLM의 랭킹 성능이 향상되는 것을 알 수 있습니다(즉, LLaMA-65B > LLaMA-35B > LLaMA-13B 순). 또한 100B보다 큰 LLM이 더 우수한 랭킹을 산출한다는 것을 알 수 있습니다.
text-davinci-003과 gpt-3.5-turbo를 다른 작은 LLM과 비교하면 알 수 있습니다. 위의 결과는 제로 샷 추천 작업도 스케일링 법칙, 즉 모델 스케일링이 LLM의 랭킹 성능을 향상시킨다는 것을 나타냅니다.
4. 결론(Conclusion)
본 연구에서는 추천 시스템의 랭킹 모델 역할을 하는 LLM의 성능에 대해 살펴보았습니다. 구체적으로, 추천 작업을 조건부 랭킹 작업으로 공식화하여 순차적인 과거 상호작용을 조건으로, 후보 생성 모델에서 검색된 상품을 후보로 간주했습니다. LLM으로 순위를 매기기 위해 후보뿐만 아니라 과거 상호작용을 포함하는 자연어 프롬프트를 추가로 구성했습니다. 그런 다음 LLM이 순차적 행동의 순서를 인식할 수 있도록 특별히 고안된 몇 가지 프롬프트 전략을 제안합니다. 또한 LLM 기반 랭킹 모델이 겪을 수 있는 위치 편향 문제를 완화하기 위한 간단한 부트스트랩 전략도 소개합니다. 광범위한 경험적 연구에 따르면 LLM은 제로 샷 랭킹에 유망한 능력을 가지고 있습니다. 또한 몇 가지 주요 연구 결과를 바탕으로 (1) 순차적인 과거 상호작용의 순서를 더 잘 인식하고, (2) 더 많은 과거 상호작용과 후보를 더 잘 활용하며, (3) 위치 편향과 인기 편향을 완화하는 등 LLM의 랭킹 능력을 더욱 향상시킬 수 있는 몇 가지 유망한 방향을 조명하고자 합니다. 향후 작업에서는 제로 샷 랭커로 LLM을 배포할 때 위에서 언급한 주요 과제를 해결하기 위한 기술적 접근 방식을 개발하는 것을 고려하고 있습니다. 또한 효과적인 개인화 추천을 위해 다운스트림 사용자 행동에 따라 효율적으로 조정할 수 있는 LLM 기반 추천 모델을 개발하고자 합니다.
참고문헌(References)
[1] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NeurIPS, 33:1877–1901, 2020.
[2] Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. Bias and debias in recommender system: A survey and future directions. CoRR, abs/2010.03240, 2020.
[3] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023.
[4] Paul Covington, Jay Adams, and Emre Sargin. Deep neural networks for youtube recommendations. In RecSys, pages 191–198, 2016.
[5] Sunhao Dai, Ninglu Shao, Haiyuan Zhao, Weijie Yu, Zihua Si, Chen Xu, Zhongxiang Sun, Xiao Zhang, and Jun Xu. Uncovering chatgpt’s capabilities in recommender systems. arXiv preprint arXiv:2305.02182, 2023.
[6] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In NAACL, 2019.
[7] Hao Ding, Yifei Ma, Anoop Deoras, Yuyang Wang, and Hao Wang. Zero-shot recommender systems. arXiv:2105.08318, 2021.
[8] Zican Dong, Tianyi Tang, Lunyi Li, and Wayne Xin Zhao. A survey on long text modeling with transformers. arXiv preprint arXiv:2302.14502, 2023.
[9] Yunfan Gao, Tao Sheng, Youlin Xiang, Yun Xiong, Haofen Wang, and Jiawei Zhang. Chat-rec: Towards interactive and explainable llms-augmented recommender system. arXiv preprint arXiv:2303.14524, 2023.
[10] Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5). In RecSys, 2022.
[11] Qingyu Guo, Fuzhen Zhuang, Chuan Qin, Hengshu Zhu, Xing Xie, Hui Xiong, and Qing He. A survey on knowledge graph-based recommender systems. TKDE, 34(8):3549–3568, 2020.
[12] F Maxwell Harper and Joseph A Konstan. The movielens datasets: History and context. TIIS, 5(4):1–19, 2015.
[13] Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yong-Dong Zhang, and Meng Wang. Lightgcn: Simplifying and powering graph convolution network for recommendation. In SIGIR, 2020.
[14] Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. Session-based recommendations with recurrent neural networks. In ICLR, 2016.
[15] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
[16] Yupeng Hou, Zhankui He, Julian McAuley, and Wayne Xin Zhao. Learning vector-quantized item
representation for transferable sequential recommenders. In WWW, 2023.
[17] Yupeng Hou, Binbin Hu, Zhiqiang Zhang, and Wayne Xin Zhao. Core: Simple and effective session-based recommendation within consistent representation space. In SIGIR, 2022.
[18] Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. Towards universal sequence representation learning for recommender systems. In KDD, 2022.
[19] Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation. In ICDM, 2018.
[20] Donald E Knuth, James H Morris, Jr, and Vaughan R Pratt. Fast pattern matching in strings. SIAM journal on computing, 6(2):323–350, 1977.
[21] Guo Lin and Yongfeng Zhang. Sparks of artificial general recommender (agr): Early experiments with chatgpt. arXiv preprint arXiv:2305.04518, 2023.
[22] Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In ACL, 2022.12
[23] Jianmo Ni, Jiacheng Li, and Julian McAuley. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. In EMNLP, pages 188–197, 2019.
[24] Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446, 2021.
[25] Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. BPR: bayesian personalized ranking from implicit feedback. In UAI, 2009.
[26] Stephen E. Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retr., 3(4):333–389, 2009.
[27] Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker,
Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal V. Nayak, Debajyoti
Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Févry, Jason Alan Fries, Ryan Teehan, Teven Le Scao, Stella Biderman, Leo Gao, Thomas Wolf, and Alexander M. Rush. Multitask prompted training enables zero-shot task generalization. In ICLR, 2022.
[28] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[29] Lei Wang and Ee-Peng Lim. Zero-shot next-item recommendation using large pretrained language models. arXiv preprint arXiv:2304.03153, 2023.
[30] Wenjie Wang, Xinyu Lin, Fuli Feng, Xiangnan He, and Tat-Seng Chua. Generative recommendation: Towards next-generation recommender paradigm. arXiv preprint arXiv:2304.03516, 2023.
[31] Xiaolei Wang, Kun Zhou, Ji-Rong Wen, and Wayne Xin Zhao. Towards unified conversational recommender systems via knowledge-enhanced prompt learning. In KDD, 2022.
[32] Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. Finetuned language models are zero-shot learners. In ICLR, 2022.
[33] Lanling Xu, Zhen Tian, Gaowei Zhang, Junjie Zhang, Lei Wang, Bowen Zheng, Yifan Li, Jiakai Tang, Zeyu Zhang, Yupeng Hou, Xingyu Pan, Wayne Xin Zhao, Xu Chen, and Ji-Rong Wen. Towards a more user-friendly and easy-to-use benchmark library for recommender systems. In SIGIR, 2023.
[34] Junjie Zhang, Ruobing Xie, Yupeng Hou, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. Recommendation as instruction following: A large language model empowered recommendation approach. arXiv preprint arXiv:2305.07001, 2023.
[35] Wayne Xin Zhao, Yupeng Hou, Xingyu Pan, Chen Yang, Zeyu Zhang, Zihan Lin, Jingsen Zhang, Shuqing Bian, Jiakai Tang, Wenqi Sun, Yushuo Chen, Lanling Xu, Gaowei Zhang, Zhen Tian, Changxin Tian, Shanlei Mu, Xinyan Fan, Xu Chen, and Ji-Rong Wen. Recbole 2.0: Towards a more up-to-date recommendation library. In CIKM, 2022.
[36] Wayne Xin Zhao, Shanlei Mu, Yupeng Hou, Zihan Lin, Yushuo Chen, Xingyu Pan, Kaiyuan Li, Yujie Lu, Hui Wang, Changxin Tian, Yingqian Min, Zhichao Feng, Xinyan Fan, Xu Chen, Pengfei Wang, Wendi Ji, Yaliang Li, Xiaoling Wang, and Ji-Rong Wen. Recbole: Towards a unified, comprehensive and efficient framework for recommendation algorithms. In CIKM, 2021.
[37] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
[38] Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate before use: Improving few-shot performance of language models. In ICML, 2021.
[39] Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In CIKM, 2020.
A. ML-1M Dataset을 사용한 예제
A.1 Sequential Prompting
- Input:
I’ve watched the following movies in the past in order:
[’0. The Matrix’, ’1. Terminator2: Judgment Day’, ’2. Roger & Me’, ’3. Fargo’, ’4. The Blair Witch Project’]
Now there are 20 candidate movies that I can watch next:
[’0. Nixon’, ’1. X-Men’, ’2. Best Men’, “3. Carlito’s Way”, ’4. Star Trek IV: The Voyage Home’, ’5. The Five Senses’, ’6. Mephisto’, ’7. Meatballs 4’, ’8. The Stupids’, ’9. Thunderball’, ’10. Body Parts’, ’11. Grumpier Old Men’, ’12. The Wedding Singer’, ’13. Ronin’, ’14. Apple, The (Sib)’, ’15. Tampopo’, ’16. The Goodbye Girl’, ’17. Force of Evil’, ’18. The Edge’, ’19. Klute’]
Please rank these 20 movies by measuring the possibilities that I would like to watch next most, according to my watching history. Please think step by step.
Please show me your ranking results with order numbers. Split your output with line break. You MUST rank the given candidate movies. You can not generate movies that are not in the given candidate list.
- Output:
- X-Men
- Carlito’s Way
- Ronin
- The Edge
- Nixon
- Grumpier Old Men
- The Wedding Singer
- Thunderball
- Body Parts
- Star Trek IV: The Voyage Home
- Tampopo
- Klute
- The Goodbye Girl
- Force of Evil
- Best Men
- The Five Senses
- Mephisto
- Meatballs 4
- The Stupids
- Apple, The (Sib)
- Result: 정답은 “X-Men”, Ranking이 0로 나옴(0부터 시작한다 했을 때)
A.2 Recency-focused Prompting
- Input:
I’ve watched the following movies in the past in order:
[’0. Eyes Wide Shut’, ’1. Fight Club’, “2. The General’s Daughter”, ’3. Gone in 60 Seconds’, ’4. Gladiator’]
Now there are 20 candidate movies that I can watch next:
[’0. For Whom the Bell Tolls’, ’1. Encino Man’, ’2. The Pope of Greenwich Village’, ’3. I Married A Strange Person’, ’4. Daylight’, ’5. Rain’, ’6. Children of a Lesser God’, “7. She’s the One”, ’8. For the Moment’, ’9. Once Upon a Time in America’, ’10. The Truth About Cats & Dogs’, “11. A Hard Day’s Night”, ’12. Jakob the Liar’, ’13. Angel Heart’, ’14. Galaxy Quest’, ’15. The Abominable Snowman’, ’16. Bait’, ’17. Warriors of Virtue’, ’18. Three to Tango’, ’19. Heaven & Earth’]
Please rank these 20 movies by measuring the possibilities that I would like to watch next most, according to my watching history. Please think step by step.
Note that my most recently watched movie is Gladiator. Please show me your ranking results with order numbers. Split your output with line break. You MUST rank the given candidate movies. You can not generate movies that are not in the given candidate list.
- Output:
- Once Upon a Time in America
- Angel Heart
- The Truth About Cats & Dogs
- Galaxy Quest
- Jakob the Liar
- A Hard Day’s Night
- The Pope of Greenwich Village
- Rain
- For Whom the Bell Tolls
- Three to Tango
- She’s the One
- Bait
- I Married A Strange Person
- Children of a Lesser God
- Warriors of Virtue
- Heaven & Earth
- Encino Man
- Daylight
- The Abominable Snowman
- For the Moment
Result: 정답은 “Jakob the Liar”, Ranking이 4로 나옴(0부터 시작한다 했을 때)
A.3 In-context learning
- Input:
I’ve watched the following movies in the past in order:
[’0. Mirror, The (Zerkalo)’, ’1.The 39 Steps’, ’2. Sanjuro’, ’3. Trouble in Paradise’]
Then if I ask you to recommend a new movie to me according to my watching history, you should recommend Shampoo and now that I’ve just watched Shampoo, there are 20 candidate movies that I can watch next:
[’0. Manon of the Spring (Manon des sources)’, ’1. Air Bud’, ’2. Citizen Kane’, ’3. Grand Hotel’, ’4. A Very Brady Sequel’, ’5. 42 Up’, ’6. Message to Love: The Isle of Wight Festival’, ’7. Screamers’, ’8. The
Believers’, ’9. Hamlet’, ’10. Cliffhanger’, ’11. Three Wishes’, ’12. Nekromantik’, ’13. Dangerous Minds’, ’14. The Prophecy’, ’15. Howling II: Your Sister Is a Werewolf ’, ’16. World of Apu, The (Apur Sansar)’, ’17. The Breakfast Club’, ’18. Hoop Dreams’, ’19. Eddie’]
Please rank these 20 movies by measuring the possibilities that I would like to watch next most, according to my watching history. Please think step by step.
Please show me your ranking results with order numbers. Split your output with line break. You MUST rank the given candidate movies. You can not generate movies that are not in the given candidate list.
- Output:
- Manon of the Spring (Manon des sources)
- Citizen Kane
- Grand Hotel
- Hamlet
- The Breakfast Club
- Hoop Dreams
- Eddie
- Three Wishes
- The Prophecy
- Dangerous Minds
- World of Apu, The (Apur Sansar)
- Cliffhanger
- A Very Brady Sequel
- Screamers
- Howling II: Your Sister Is a Werewolf
- Nekromantik
- 42 Up
- Message to Love: The Isle of Wight Festival
- Air Bud
- The Believers
- Result: 정답은 “World of Apu, The (Apur Sansar)”, Ranking이 10로 나옴(0부터 시작한다 했을 때)
B. Games을 사용한 예제
B.1 Sequential Prompting
- Input:
I’ve purchased the following products in the past in order:
[’0. Sony PlayStation 3 Blu-ray Disc Remote’, ’1. PlayStation 3 160GB System with Ratchet & Clank Future: A Crack in Time and SingStar Dance Party Pack - Family Bundle’, ’2. PS3 320GB Uncharted 3 Bundle’, ’3. FIFA Soccer 10 - Playstation 3’]
Now there are 20 candidate products that I can consider to purchase next:
[’0. Wii 9 in 1 Sports Kit’, ’1. Donkey Kong’, ’2. Midnight Club’, ’3. Midnight Club’, ’4. SRS: Street Racing Syndicate - PlayStation 2’, ’5. Ultimate Action Triple Pack - PlayStation 3’, ’6. Thrustmaster TMX Force Feedback racing wheel for Xbox One and WINDOWS’, ’7. Pikmin 2 (Nintendo Selects) - Nintendo Wii’, ’8. Rock Candy Blueberry Boom’, ’9. Finding Nemo - Gamecube’, ’10. SteelSeries Siberia 200 Gaming Headset - Alchemy Gold (formerly Siberia v2)’, ’11. Konnet Xbox 360 / Slim Power Pyramid RCS series Charger, Charging and Storage Dock for FOUR Game Controllers - Black’, ’12. Megadream Xbox One Wireless Keyboard, Mini 2.4Ghz Qwerty Text Message Chatpad Keypad for Microsoft Xbox One and Xbox One Slim Controller - Not Compatible with Xbox One Elite and X Controller’, ’13. Theme Hospital - PlayStation’, ’14. Spongebob Hero Pants The Game 2015 - Xbox 360’, ’15. Megaman & Bass’, ’16. BW® 5 Pair/10 Pcs Replacement Silicone Analog Controller Joystick Thumb Stick Grips Cap Cover For PS3 / PS4 / Xbox 360 / Xbox One / Wii Game Controllers (green)’, ’17. Skylanders Giants Battlepack #1 - Chop Chop - Dragonfire Cannon - Shroomboom’, ’18. Rune Factory: Tides of Destiny - Playstation 3’, ’19. Donkey Kong Land III’]
Please rank these 20 products by measuring the possibilities that I would like to purchase next most, according to the given purchasing records. Please think step by step.
Please only output the order numbers after ranking. Split these order numbers with line break.
- Output:
- 1
- 5
- 6
- 10
- 11
- 12
- 16
- 17
- 18
- 2
- 0
- 7
- 8
- 9
- 13
- 14
- 15
- 3
- 4
- 19
- Result: 정답은 “Midnight Club”, Ranking이 9로 나옴(0부터 시작한다 했을 때)
B.2 Recency-focused Prompting
- Input:
I’ve purchased the following products in the past in order:
[’0. PowerA DualShock 4 Charging Station for PlayStation 4’, ’1. Far Cry 4 - PlayStation 4’, ’2. WWE 2K17 - PlayStation 4’, ’3. Dragon Quest Builders - PlayStation 4’]
Now there are 20 candidate products that I can consider to purchase next:
[’0. Ready to Rumble Boxing: Round 2’, ’1. Insten USB Charger Charging Cable Replacement For Nintendo NEW 3DS XL / NEW 2DS XL / 3DS XL / 3DS / 2DS / DSi / DSi XL / DSi LL’, “2. Cabela’s African Adventures - Xbox 360”, ’3. Blood Bowl - Xbox 360’, ’4. Skullcandy SLYR Gaming Headset, White (SMSLFY-205 )’, ’5. HORI 3DS Protector and Pouch Set (Mario Kart 7 version)’, ’6. Grand Theft Auto V - PlayStation 4’, “7. Yoshi’s New Island Full Game Download Code - Nintendo 3DS eShop”, ’8. Gauntlet’, ’9. Solitaire & Mahjong - Nintendo Wii’, ’10. Happy Feet 2 - Playstation 3’, ’11. Little Italy - Hidden Object Games [Download]’, ’12. Jillian Michaels Fitness Adventure - Xbox 360’, ’13. Dream Day Wedding: Viva Las Vegas - PC’, ’14. NBA Inside Drive 2003’, ’15. The Sims 2 - Sony PSP’, ’16. Xenogears - PlayStation’, ’17. Combat’, ’18. Crash Bandicoot: The Wrath of Cortex - Gamecube’, ’19. Sonic Mega Collection’]
Please rank these 20 products by measuring the possibilities that I would like to purchase next most, according to the given purchasing records. Please think step by step.
Note that my most recently purchased product is Dragon Quest Builders - PlayStation 4. Please only output the order numbers after ranking. Split these order numbers with line break.
- Output:
- 6
- 0
- 4
- 2
- 7
- 18
- 16
- 3
- 1
- 8
- 19
- 13
- 12
- 11
- 10
- 5
- 9
- 15
- 14
- 17
- Result: 정답은 “Grand Theft Auto V - PlayStation 4”, Ranking이 0로 나옴(0부터 시작한다 했을 때)
B.3 In-context Learning
- Input:
I’ve purchased the following products in the past in order:
[’0. Scooby-Doo Unmasked - PlayStation 2’, ’1. Scooby-Doo: Mystery Mayhem’, ’2. Thrillville: Off the Rails’, ’3. Pac Man World 2 - PlayStation 2’]
Then if I ask you to recommend a new product to me according to the given purchasing history, you should recommend Charlie and the Chocolate Factory - PlayStation 2 and now that I’ve just purchased Charlie and the Chocolate Factory - PlayStation 2, there are 20 candidate products that I can consider to purchase next:
[’0. Controller Gear Controller Stand v1.0 - Officially Licensed - Black - Xbox One’, ’1. NHL 08 - PlayStation 2’, ’2. Hyperdimension Neptunia Victory - Playstation 3’, ’3. DOOM [Online Game Code]’, ’4. Sega Dreamcast Controller’, ’5. Mayflash F300 Arcade Fight Stick Joystick for PS4 PS3 XBOX ONE XBOX 360 PC Switch NeoGeo mini’, ’6. Fallout New Vegas Ultimate Edition’, ’7. Star Wars Galactic Battlegrounds: Clone
Campaigns (Expansion Pack)’, ’8. Hatsune Miku: Project DIVA X - PlayStation 4’, ’9. GameMaster Sony PS Vita Anti-Bacterial Screen Protector’, ’10. NBA 2K9’, ’11. Dragon Ball Xenoverse - Xbox One’, ’12. Enhanced Thumb Grips Quad Pack BRAND NEW for Playstation Vita’, ’13. Dead Rising 3: Apocalypse Edition’, ’14. Hitman 2 Silent Assassin - Xbox’, ’15. Dracula Resurrection - PC’, ’16. Jekyll and Hyde - PC’, ’17. Thief - Playstation 3’, ’18. MyLifeUNIT Hand Grip Handle Stand for Nintendo New 3DS XL LL’, ’19. Sony PSP-1001K PlayStation Portable (PSP) System (Black)’]
Please rank these 20 products by measuring the possibilities that I would like to purchase next most, according to the given purchasing records. Please think step by step.
Please only output the order numbers after ranking. Split these order numbers with line break.
- Output:
- 1
- 6
- 13
- 7
- 11
- 3
- 14
- 17
- 0
- 2
- 8
- 10
- 18
- 5
- 9
- 15
- 16
- 4
- 12
- 19
- Result: 정답은 “NHL 08 - PlayStation 2”, Ranking이 0로 나옴(0부터 시작한다 했을 때)
'ML > Recsys' 카테고리의 다른 글
| (미완)[Recsys] About News-domain (0) | 2020.11.10 |
|---|---|
| (미완)[Recsys]추천 시스템 관련 article 정리(NAVER) (0) | 2020.11.01 |
| [Recsys] 추천 시스템의 목적을 잊지 말자. (0) | 2020.10.26 |
| [Recsys]추천 시스템의 큰 Flowchart (0) | 2020.10.26 |
| [Recsys]Collaborative filtering 장단점 (0) | 2020.10.20 |