우리가 어떤 class의 object를 만들 때면, 각 object마다 dictionary가 할당되는데, 이는 object의 attribute를 저장해두기 위함이다. 이는 dictionary다 보니까 메모리를 꽤나 차지한다. 다수의 object를 만들 때면 이러한 메모리들이 쌓여 태산이 된다.
사용할 상황:
class에 attibutes가 제한되어 있다면(즉 향후에 dynamic하게 attributes를 추가하거나 하는 작업이 없다면)
__slots__로 attribute를 제한하고 시작하고, 이렇게 되면 dictionary를 사용하지 않아 메모리를 절약함과 동시에
attribute 접근 속도도 빨라진다.
사용법:
class attribute로 __slots__ = ['att1', 'att2'] 형태로, 사용할 attributes를 선언하면,
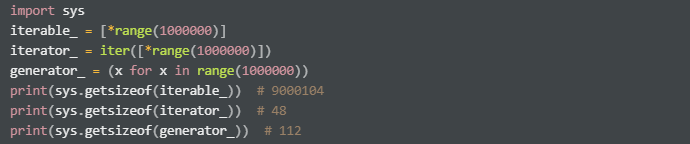
헷갈리는 Iterator, Iterable 개념의 공통점과 차이를 보아 확실히 이해해보자.
명확한 정의를 알아보자. 단순히 특징을 알아보는게 아니다.
즉, Iterable은 for-loop을 돌 수 있는 것, 따위 형태로 알아보자는 것이 아니라,
정확한 정의를 통해 성질을 알아보는 형태로 작성한다.
Iterable->Iterator->Generator 순으로 알아보자.
Iterable이란
An object capable of returning its members one at a time. Examples of iterables include all sequence types (such as list, str, and tuple) and some non-equence types like dict, file objects, and objects of any classes you define with an __iter__() method or with a __getitem__() method that implements Sequence semantics.
Iterator란
Iterators are required to have both __iter__() method that returns the iterator object itself so every iterator is also iterable and __next__() method.
Generator란, 아래 2개 중 하나를 가리킬 때 쓰는데, 여기서는 후자를 가리킨다.
-generator function란
function which returns a generator iterator. It looks like a normal function except that it contains yield expressions for producing a series of values usable in a for-loop or that can be retrieved one at a time with the next() function.
-generator iterator란
An object created by a generator function.
비고:
generator iterator는 생성하면 반드시 __iter__() method와 __next__() method를 갖는다.
따라서 generator는 반드시 iterator이다.
iteration을 돌 때 순차적인 값을 얻는 것에만 관심있다면 generator만으로 족하다.
하지만, 현재 current state를 조회한다는 등의 추가적인 method가 필요하다면 iterator를 직접 정의하여 사용하자.
따라서 다음 포함관계가 성립한다.
generator ⊂ iterator ⊂ iterable
위 3개의 개념을 헷갈리게 만드는 주범으로는
from collections.abc import Iterable
isinstance([object], Iterable)
-> 위에서 정의한 Iterable을 판단하기에 완벽하지 않다.
object가 만약 __getitem__() method만 갖는 object면 False를 반환한다.
그렇다면 정확한 Iterable 객체임을 판단하는 방법은 무엇인가?
iter([object])을 씌웠을 때 error가 안뜨면 object는 iterable 객체이다.
Iterable 객체가 loop을 돌 때 작동하는 방식은
-iter을 씌운 다음에
-next해서 원소들을 반환함
Iterable, Iterator, Generator를 각각 언제 쓸 것인가?
순환하고 값 조회를 더이상 할 필요가 없다면 iterator/generator를 사용
이 때, 순차적인 1회성 조회할 iterator를 만들 것이면 generator를 사용
순환하면서도 current state같은 것을 조회하려면 (custom) iterator를 사용
iter() function은 무엇인가?
Return an iterator object. The first argument is interpreted very differently depending on the presence of the second argument. Without a second argument, object must be a collection object which supports the iteration protocol (the __iter__() method), or it must support the sequence protocol (the __getitem__() method with integer arguments starting at 0). If it does not support either of those protocols, TypeError is raised. If the second argument, sentinel, is given, then object must be a callable object. The iterator created in this case will call object with no arguments for each call to its __next__() method; if the value returned is equal to sentinel, StopIteration will be raised, otherwise the value will be returned.
즉 sentinel(=보초병, 감시병)값이 argument로 넣냐 안넣냐에 따라 달라진다.
안넣으면 object의 __iter__()을 실행시켜 iterator를 반환한다.
넣으면 first argument는 반드시 callable이어야하고 sentinel값이 나올 때 까지 next가 가능한 iterator를 반환한다.
후자는 callable_iterator type이 반환된다.
전자든 후자든 isinstance([object], Iterator)로 iterator 확인 가능
즉 iter(iterable) or iter(callable object, sentinel) 형태로 사용
참고자료의 마지막을 꼭 보자.(Iterator을 만드는 다양한 방법을 제시한다.)
__iter__()를 활용하여 iterable을 정의하고 __next__()을 추가하여 iterator을 만드는 예제
__getitem__()을 활용한 iterable을 정의하고 iterator을 만들어서 동작하는 예제
callable object(class with __call__() or function)와 sentinel을 활용한 iterator 생성하는 예제
Faiss is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning. Faiss is written in C++ with complete wrappers for Python/numpy. Some of the most useful algorithms are implemented on the GPU. It is developed by Facebook AI Research.
Faiss의 특징
즉, dense vector databases에서 query vector와 가장 유사한 vector를 뽑는 효율적인 알고리즘이다.
CPU, GPU 기반으로 작동하게 할 수 있으며,
IVF(InVerted File index)를 활용
L2 distance, Dot product(L2 normalization하면 cosine similarity도 가능)가 가능
binary vectors and compact quantization vectors(PCA, Product Quantization사용)를 활용
따라서 original vectors를 keep하지 않아 낮은 RAM으로도 billions vector database에 적용 가능
Multi-GPU 사용도 제공
Batch processing 제공
L2, inner product, L1, Linf 등의 distance 제공
query vector의 radius 내의 모든 vectors in DB를 return할 수도 있음